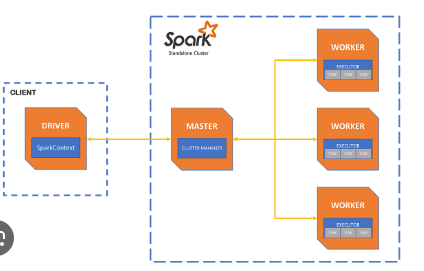
 par
par Apache Spark est un moteur de traitement de données distribué open-source utilisé pour les tâches de big data et d’analytique. En utilisant Docker, vous pouvez facilement déployer et gérer Spark de manière isolée et portable. Ce guide détaillé vous montrera comment mettre en place Apache Spark sur Docker, couvrant toutes les étapes essentielles pour une installation réussie et optimisée.
Introduction à Spark et Docker
Qu’est-ce qu’Apache Spark ?
Apache Spark est un moteur de traitement de données rapide et généraliste conçu pour traiter de grandes quantités de données. Il supporte plusieurs langages de programmation comme Scala, Java, Python et R, et il est largement utilisé pour des tâches telles que le traitement par lots, le traitement en temps réel, l’apprentissage automatique et l’analyse graphique.
Qu’est-ce que Docker ?
Docker est une plateforme open-source qui permet de créer, déployer et gérer des applications dans des conteneurs isolés. Ces conteneurs incluent tout ce dont une application a besoin pour fonctionner, assurant une portabilité et une consistance accrues.
Pré-requis
Avant de commencer, assurez-vous d’avoir les éléments suivants installés sur votre machine :
- Docker : Téléchargez et installez Docker depuis le site officiel docker.com.
- Un terminal ou un shell de commande : Pour exécuter les commandes Docker.
- Docker Compose : Pour gérer des applications multi-conteneurs.
Étapes pour Mettre en Place Spark sur Docker
Étape 1 : Télécharger l’Image Spark
La première étape consiste à télécharger l’image officielle de Spark depuis le Docker Hub. Utilisez la commande suivante pour cela :
bash
docker pull bitnami/spark:latest
Étape 2 : Créer un Réseau Docker
Pour permettre la communication entre les conteneurs Spark, créez un réseau Docker :
bash
docker network create spark-network
Étape 3 : Démarrer le Master Spark
Lancez le conteneur pour le Master Spark en utilisant la commande suivante :
bash
docker run -d --name spark-master --network spark-network -p 8080:8080 -p 7077:7077 bitnami/spark:latest ./bin/spark-class org.apache.spark.deploy.master.Master
Explications des options utilisées dans la commande :
-d: Exécute le conteneur en arrière-plan.--name spark-master: Donne un nom au conteneur, ici « spark-master ».--network spark-network: Connecte le conteneur au réseau Docker « spark-network ».-p 8080:8080et-p 7077:7077: Mappe les ports pour accéder à l’interface web et au service Spark.
Étape 4 : Démarrer les Workers Spark
Lancez un ou plusieurs conteneurs pour les Workers Spark en utilisant la commande suivante :
bash
docker run -d --name spark-worker-1 --network spark-network -e SPARK_MASTER=spark://spark-master:7077 bitnami/spark:latest ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
Explications des options supplémentaires :
-e SPARK_MASTER=spark://spark-master:7077: Définit l’URL du Master Spark que le Worker doit utiliser.
Répétez cette commande pour ajouter plus de Workers si nécessaire.
Étape 5 : Vérifier l’Installation
Pour vérifier que Spark est correctement configuré, accédez à l’interface web du Master Spark à l’adresse suivante :
arduino
http://localhost:8080
Vous devriez voir l’interface de gestion de Spark, où les Workers et les tâches seront listés.
Configuration Avancée
Utiliser Docker Compose
Docker Compose permet de définir et de gérer des applications multi-conteneurs. Créez un fichier docker-compose.yml pour gérer Spark :
yaml
version: '3'
services:
spark-master:
image: bitnami/spark:latest
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
networks:
- spark-network
command: ./bin/spark-class org.apache.spark.deploy.master.Masterimage: bitnami/spark:latest
container_name: spark-worker-1
environment:
– SPARK_MASTER=spark://spark-master:7077
networks:
– spark-network
command: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
image: bitnami/spark:latest
container_name: spark-worker-2
environment:
– SPARK_MASTER=spark://spark-master:7077
networks:
– spark-network
command: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
spark-network:
driver: bridge
Déployez les services en utilisant la commande suivante :
bash
docker-compose up -d
Montage de Volumes pour la Persistance des Données
Pour persister les données, montez des volumes Docker. Par exemple, pour persister les journaux Spark :
yaml
version: '3'
services:
spark-master:
image: bitnami/spark:latest
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- /path/to/spark/logs/master:/opt/bitnami/spark/logs
networks:
- spark-network
command: ./bin/spark-class org.apache.spark.deploy.master.Masterimage: bitnami/spark:latest
container_name: spark-worker-1
environment:
– SPARK_MASTER=spark://spark-master:7077
volumes:
– /path/to/spark/logs/worker-1:/opt/bitnami/spark/logs
networks:
– spark-network
command: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
spark-network:
driver: bridge
Remplacez /path/to/spark/logs par les chemins des répertoires sur votre hôte où vous souhaitez stocker les journaux.
Optimisation des Performances
Ajustement des Ressources
Assurez-vous que votre machine hôte dispose de suffisamment de CPU et de mémoire pour gérer les tâches Spark. Vous pouvez également ajuster les limites de ressources pour les conteneurs Docker :
yaml
services:
spark-worker-1:
image: bitnami/spark:latest
container_name: spark-worker-1
environment:
- SPARK_MASTER=spark://spark-master:7077
deploy:
resources:
limits:
memory: 2g
cpus: '1.0'
networks:
- spark-network
command: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
Configuration des Paramètres Spark
Pour optimiser les performances, configurez les paramètres Spark dans le fichier spark-defaults.conf. Montez ce fichier dans le conteneur :
yaml
services:
spark-master:
image: bitnami/spark:latest
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- /path/to/spark-defaults.conf:/opt/bitnami/spark/conf/spark-defaults.conf
networks:
- spark-network
command: ./bin/spark-class org.apache.spark.deploy.master.Master
Sécurisation de Spark
Configuration SSL/TLS
Pour sécuriser les communications, configurez SSL/TLS en ajoutant les paramètres SSL dans le fichier spark-defaults.conf :
plaintext
spark.ssl.enabled true
spark.ssl.keyPassword password
spark.ssl.keyStore /path/to/keystore.jks
spark.ssl.keyStorePassword password
spark.ssl.trustStore /path/to/truststore.jks
spark.ssl.trustStorePassword password
Montez les fichiers de certificats dans le conteneur :
yaml
services:
spark-master:
image: bitnami/spark:latest
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- /path/to/spark-defaults.conf:/opt/bitnami/spark/conf/spark-defaults.conf
- /path/to/keystore.jks:/opt/bitnami/spark/conf/keystore.jks
- /path/to/truststore.jks:/opt/bitnami/spark/conf/truststore.jks
networks:
- spark-network
command: ./bin/spark-class org.apache.spark.deploy.master.Master
Surveillance et Gestion
Utiliser des Outils de Surveillance
Pour surveiller les performances de Spark, utilisez des outils comme Prometheus et Grafana. Configurez Spark pour exporter des métriques et les intégrer avec Prometheus.
Utiliser Docker Compose pour une Gestion Simplifiée
Docker Compose permet de gérer facilement les mises à jour et la maintenance des conteneurs. Utilisez les commandes suivantes pour arrêter, démarrer et redémarrer vos services Spark :
bash
docker-compose stop
docker-compose start
docker-compose restart
Conclusion
Installer Apache Spark sur Docker est une méthode efficace pour déployer des environnements de traitement de données distribués de manière flexible et évolutive. En suivant les étapes de ce guide, vous pouvez installer, configurer et optimiser Spark pour répondre à vos besoins spécifiques. Que vous déployiez Spark pour une application de production ou pour des tests, Docker simplifie la gestion et le déploiement, tout en offrant des performances élevées et une grande fiabilité. Profitez des avantages de cette configuration pour améliorer vos solutions de traitement de données.